タスク複雑性で「表層的アラインメント仮説(SAH)」を操作可能にする:短いプログラム長で測る適応の情報量
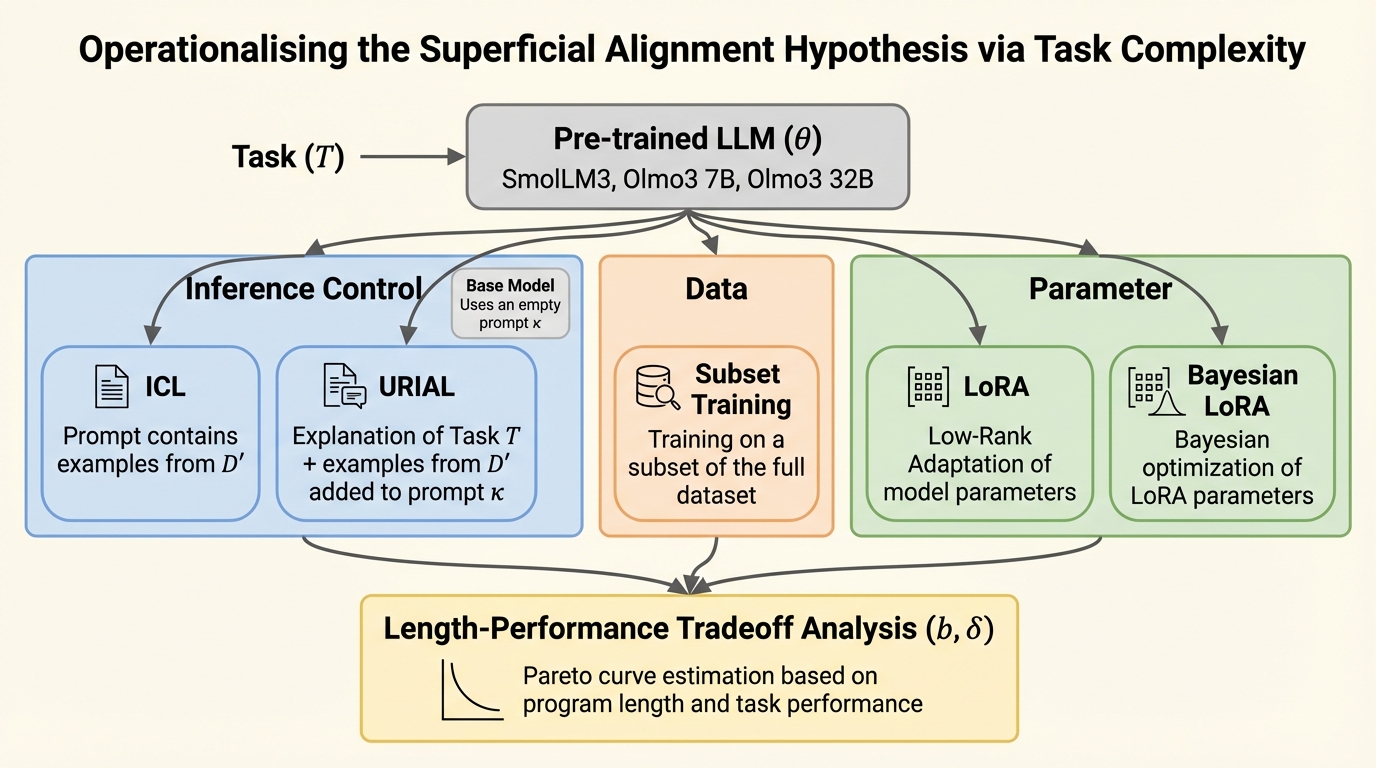
SAHは「大規模言語モデルは事前学習で知識の大半を得て、事後学習はそれを表に出すだけ」という見立てですが、重要語の定義が曖昧なため、支持と批判が同じ土俵で噛み合いにくい状況でした。 / 本研究は、目標性能を満たすための「最短プログラム長」をタスク複雑性として定義し、少量データでの微調整、少数パラメータ更新、推論時のプロンプト制御を、短いプログラムを見つけるための別戦略として同一の指標で比較できるようにします。 / 数学推論・機械翻訳・指示追従で複雑性を推定したところ、事前学習モデルへのアクセスにより複雑性が非常に小さくなり得る一方、強い性能へ到達するには長大なプログラムが必要になる場合もあり、事後学習は同等の性能へ到達する複雑性を大きく縮め、適応に必要な情報が数キロバイトで足りることが多いと示されました。
TL;DR(結論)
- SAHは「大規模言語モデルは事前学習で知識の大半を得て、事後学習はそれを表に出すだけ」という見立てですが、重要語の定義が曖昧なため、支持と批判が同じ土俵で噛み合いにくい状況でした。
- 本研究は、目標性能を満たすための「最短プログラム長」をタスク複雑性として定義し、少量データでの微調整、少数パラメータ更新、推論時のプロンプト制御を、短いプログラムを見つけるための別戦略として同一の指標で比較できるようにします。
- 数学推論・機械翻訳・指示追従で複雑性を推定したところ、事前学習モデルへのアクセスにより複雑性が非常に小さくなり得る一方、強い性能へ到達するには長大なプログラムが必要になる場合もあり、事後学習は同等の性能へ到達する複雑性を大きく縮め、適応に必要な情報が数キロバイトで足りることが多いと示されました。
なぜこの問題か
表層的アラインメント仮説(SAH)は、事前学習済みの大規模言語モデルが多くの「知識や能力」をすでに持っており、後段の学習はそれを利用しやすい形にするだけだ、という主張として語られてきました。ところが、この主張の中心にある「知識」「能力」「形式の部分集合」といった語が精密に定義されていないため、議論が分岐しやすいと本研究は指摘します。具体的には、少量データでの微調整が効くという話、更新すべきパラメータが少ないという話、重みを固定したまま推論時の工夫だけで性能が出るという話が、互いに別の現象のように見えてしまいます。これにより、支持側の論点が「直交している」かのように扱われ、共通の芯が見えにくくなります。さらに批判側は、この曖昧さを利用して別の解釈を与え、もし本当に知識や能力があるなら性能は容易に飽和するはずだ、という観点から「追加の微調整や事後学習がかなり必要なタスクがある」ことを根拠にSAHの不十分さを論じてきました。こうした対立は、結局のところ「タスクを解くために追加で必要な情報量」を観測可能な形で揃えていないことに由来します。…
核心:何を提案したのか
本研究の提案は「タスク複雑性(task complexity)」という指標で、あるタスクにおいて目標性能に到達するための最短プログラム長として定義されます。まずタスクは、入力空間と出力空間、入力分布、採点関数からなる組として定式化されます。プログラムは入力を受け取り、出力を返し、その出力が採点関数によって評価されます。性能は入力分布に関する期待値として定義され、ある閾値以上の性能を満たすプログラムのうち、最も短いものの長さがタスク複雑性になります。重要なのは、事前学習済みモデルを「追加の入力として参照できる」状況を明示した条件付きタスク複雑性です。モデル重み(トークナイザも含め、ビット列として表す)へのアクセスを許したプログラムに限定し、そのときの最短プログラム長を考えます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related