LLMエージェントにおける実行可能な意味的制約の強制のためのオントロジーからツールへのコンパイル
科学技術文献から構造化された知識を抽出する際、従来の手法では抽出後にデータの妥当性を検証する後処理が必要であったが、本研究ではオントロジーの仕様を直接実行可能なツールインターフェースへとコンパイルする新しいメカニズムを導入した。
TL;DR(結論)
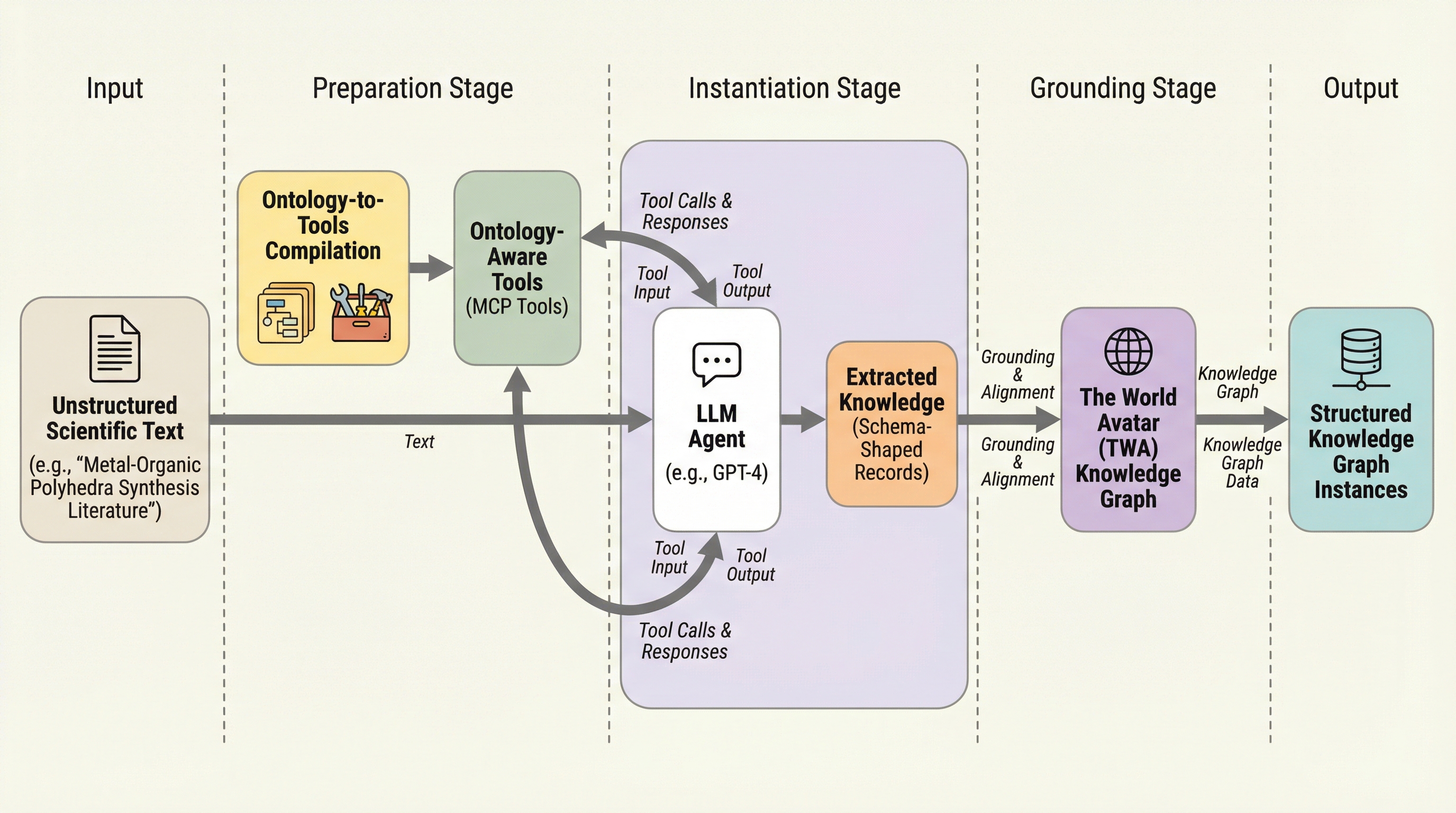
科学技術文献から構造化された知識を抽出する際、従来の手法では抽出後にデータの妥当性を検証する後処理が必要であったが、本研究ではオントロジーの仕様を直接実行可能なツールインターフェースへとコンパイルする新しいメカニズムを導入した。 この手法は「The World Avatar(TWA)」のエコシステム内で動作し、モデルコンテキストプロトコル(MCP)を通じてLLMエージェントに意味的な制約を課すことで、知識グラフのインスタンスを作成または修正する際に、生成プロセスそのものの中で制約を強制的に適用することを可能にしている。 金属有機多面体(MOP)の合成に関する学術論文を対象とした事例研究では、このフレームワークが未構造のテキストから高品質な知識を抽出し、検証および修復を反復的に行うワークフローを通じて、手動によるスキーマ設計やプロンプトエンジニアリングの負担を大幅に軽減できることを実証した。
なぜこの問題か
科学文献から機械が処理可能な構造化データを抽出することは、仮説の生成やデータ駆動型のモデリング、合成予測などの高度な科学的ワークフローを実現するために不可欠な工程である。しかし、科学的なテキストは極めて専門性が高く、正確な解釈が求められるため、未構造の文章から一貫性のある記録を作成することは依然として困難な課題として残されている。特に、抽出されたデータが下流のプロセスで有効に機能するためには、明確な役割の定義や概念の境界、正規化された単位や値、そして曖昧さのない実体参照が必要とされる。例えば、試薬が前駆体なのか溶媒なのかという役割が明示されていない場合や、実験条件が異なる単位で記載されている場合、あるいは同じ化学物質が複数の名称や略称で登場する場合などが頻繁に発生する。これらはデータ駆動型の研究において、重複の排除やクロスドメインでの統合を妨げる大きな要因となる。 これらを解決するためにオントロジーが利用されるが、従来のパイプラインでは、抽出されたデータがオントロジーに適合しているかを確認するために、抽出後に決定論的な検証や位置合わせを行う後処理層に依存していた。…
核心:何を提案したのか
本研究では、オントロジーの仕様を実行可能なLLM呼び出しツールへと変換する「オントロジーからツールへのコンパイル」という新しいフレームワークを提案した。このアプローチの核心は、意味的な制約をプロンプトや出力スキーマの制限として与えるのではなく、生成モデルが対話する実行環境そのものに組み込む点にある。具体的には、「The World Avatar(TWA)」という動的な知識グラフの枠組みの中で、オントロジーの定義(T-Box)をモデルコンテキストプロトコル(MCP)に基づいたツールインターフェースへとコンパイルする。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related