ブーストジェットタグ付けのためのニューラル・スケーリング則:JetClassで学ぶ計算量配分、反復学習、入力表現の影響
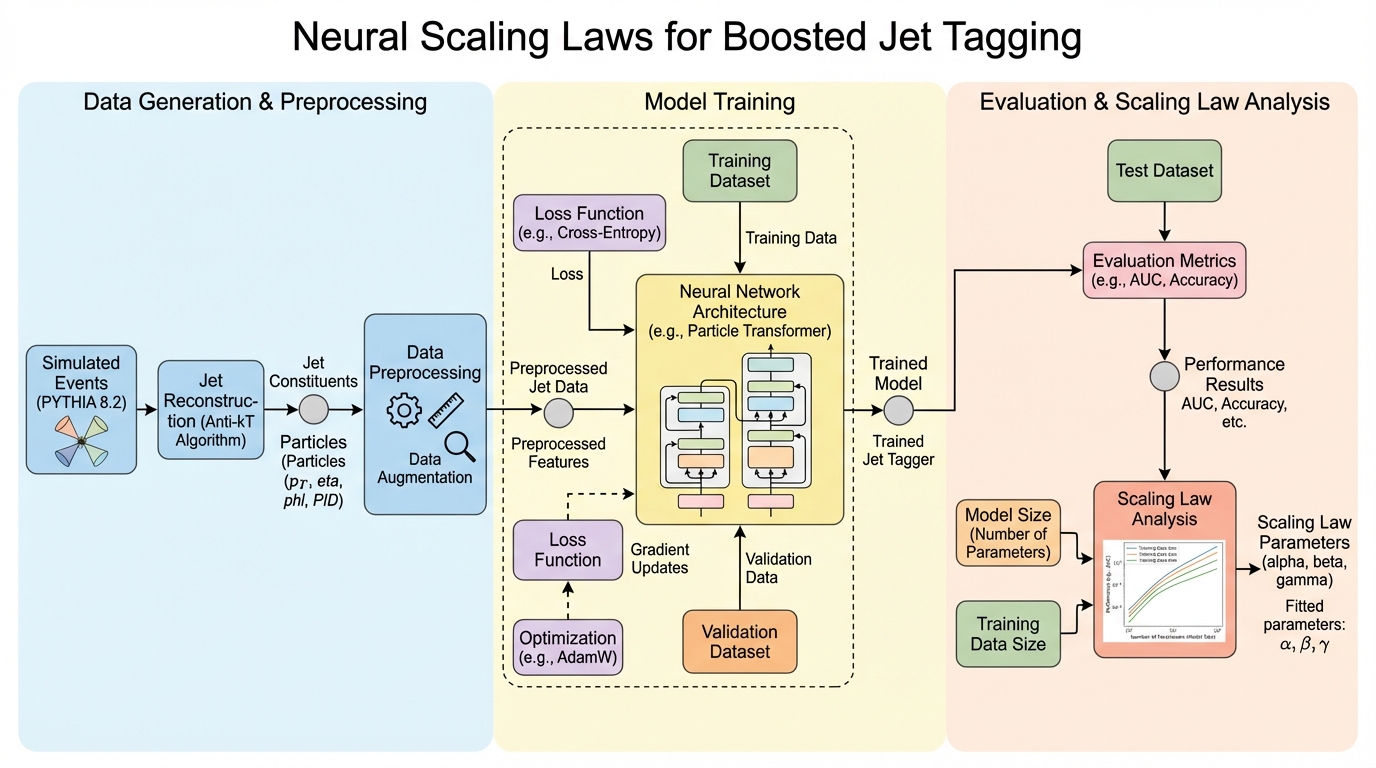
公開データセットJetClassのブーストジェット分類で、モデルのパラメータ数と学習データ数を同時に増やして学習計算量を拡張すると、検証損失が不可約損失と呼ぶ到達限界へ一貫して近づくことを、スケーリング則として整理しています。
TL;DR(結論)
- 公開データセットJetClassのブーストジェット分類で、モデルのパラメータ数と学習データ数を同時に増やして学習計算量を拡張すると、検証損失が不可約損失と呼ぶ到達限界へ一貫して近づくことを、スケーリング則として整理しています。
- Transformerエンコーダの規模と「重複なしで1回だけ見る学習データ数」を系統的に振り、損失を「不可約損失+モデル有限性の項+データ有限性の項」の形で同時フィットし、さらにデータ反復(複数エポック)がこの関係をどう変えるかも調べています。
- 計算量に対する最適スケーリングでは損失がべき的に低下し、反復学習は有効データ量の増加として定量化できる一方で利得は飽和し、入力特徴量の表現力や粒子数の選び方が到達限界(不可約損失)の水準を大きく動かすと示しています。
なぜこの問題か
高エネルギー物理の解析では、ジェットのタグ付けや事象分類、再構成、異常検知などに深層学習が広く使われています。陽子同士の衝突では、硬い散乱で生成されたクォークやグルーオンを直接観測できないため、多数の粒子がまとまったジェットとして測定されます。特に、トップクォークやHiggsボソン、W/Zボソンのような重い粒子が、その質量より十分大きい横運動量で生成されると、崩壊生成物が1つの大きな半径の「ブーストジェット」にまとまり、内部構造が親粒子の情報を運びます。したがって、ブーストジェットの分類性能をどこまで上げられるかは、実験解析に直結する重要な論点です。 一方で、近年の大規模言語モデルの成功は、モデル容量と訓練データを同時に拡張して学習計算量を増やすことが、性能向上の主要因になり得るという経験則を強く後押ししました。この経験則はニューラル・スケーリング則として、計算量に対して損失がべき則で下がること、さらに計算量が限られる状況でモデルとデータにどう資源配分するとよいかを予測する枠組みへ発展しています。…
核心:何を提案したのか
本研究が提案している中心は、ブーストジェット分類に対してニューラル・スケーリング則を明示的に当てはめ、計算量・モデル規模・データ規模の関係を定量モデルとして扱えるようにすることです。具体的には、公開データセットJetClassを用い、Transformerエンコーダのパラメータ数Nと、重複なしで用いる学習サンプル数Dを広い範囲で振りながら、検証損失Lを同時に説明する式を構築しています。損失の形は「不可約損失L∞に、有限なモデル容量に由来する項と、有限なデータ量に由来する項が加わる」という足し合わせで表し、そこから計算量制約下で最も効率的な資源配分(compute-optimal)を導きます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related