MAD: マルチモーダルLLMにおけるクロスモーダル・ハルシネーションを軽減するモダリティ適応型デコーディング
マルチモーダル大規模言語モデル(MLLM)において、あるモダリティの情報が別のモダリティの生成を不適切に歪めてしまう「クロスモーダル・ハルシネーション」を解決するため、追加学習を必要としない新しいデコーディング手法「MAD(Modality-Adaptive Decoding)」が提案された。
TL;DR(結論)
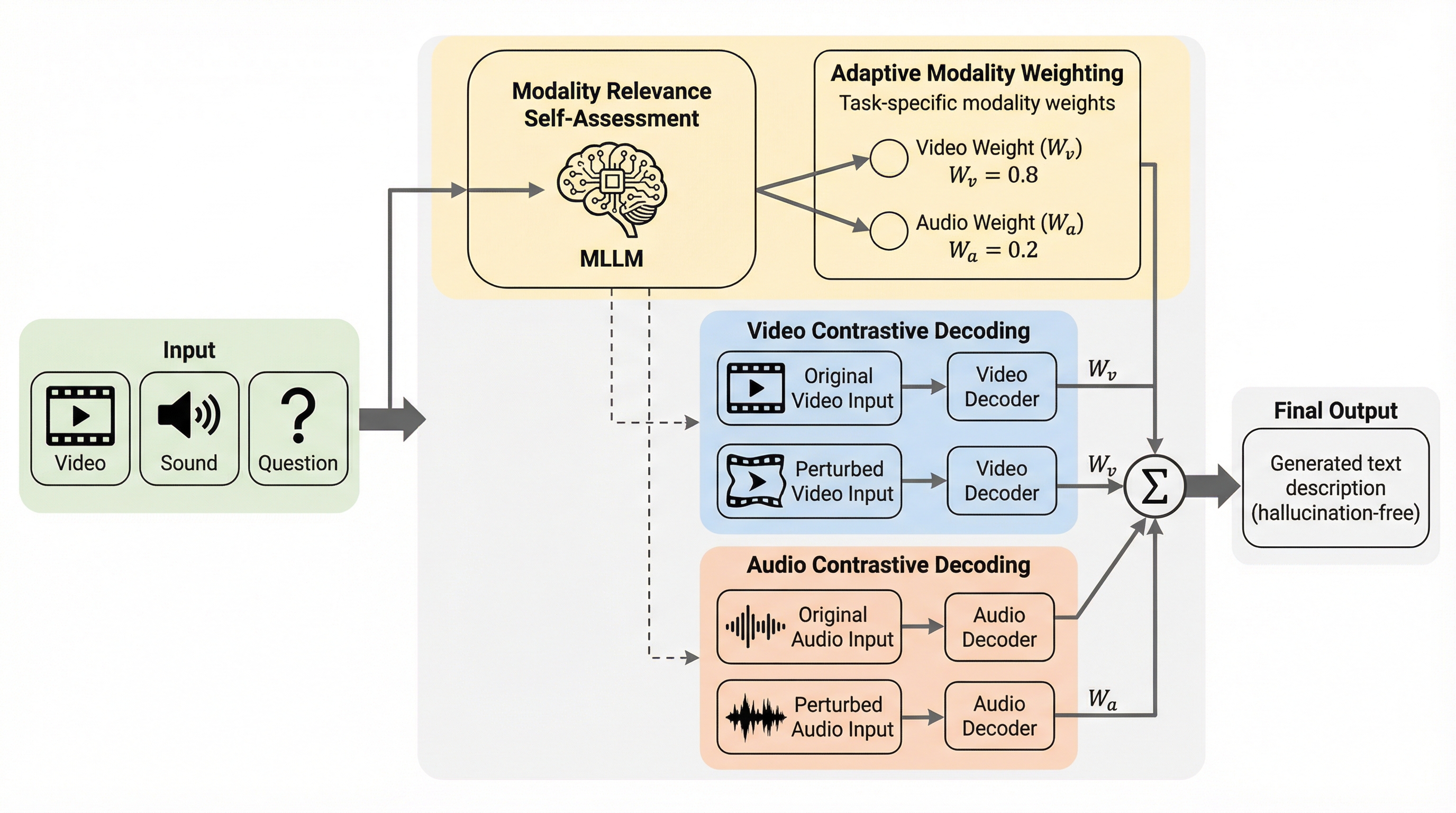
マルチモーダル大規模言語モデル(MLLM)において、あるモダリティの情報が別のモダリティの生成を不適切に歪めてしまう「クロスモーダル・ハルシネーション」を解決するため、追加学習を必要としない新しいデコーディング手法「MAD(Modality-Adaptive Decoding)」が提案された。 この手法は、モデル自身にタスク遂行に必要なモダリティ(映像、音声、またはその両方)を自己評価させ、その重要度に基づいた重みを動的に抽出することで、関連性の低いモダリティからの干渉を抑制しつつ、適切な情報源に焦点を当てたトークン生成を可能にする。 VideoLLaMA2-AVやQwen2.5-Omniを用いた実験では、CMMやAVHBenchといった主要なベンチマークにおいて最大8.7%の精度向上を達成し、既存の対照的デコーディング手法の限界を克服して、入力コンテンツに忠実な推論を実現できることが証明された。
なぜこの問題か
マルチモーダル大規模言語モデル(MLLM)は、テキストのみの処理を超えて、映像、音声、言語といった多様な感覚情報を統合することで、人間のような高度な知覚と理解を実現することを目指している。近年、CLIPやSigLIPといった視覚エンコーダ、あるいはHuBERTやWhisperといった音声エンコーダを言語モデルと統合することで、ビデオ質問回答やオーディオ・ビジュアルなシーン理解など、幅広いアプリケーションが可能になった。しかし、これらのモデルは「クロスモーダル・ハルシネーション」という、単一モダリティのハルシネーションよりも複雑で解決が困難な課題に直面している。これは、あるモダリティの情報が別のモダリティに関するコンテンツ生成に不適切な影響を及ぼし、結果として事実に基づかない出力を捏造してしまう現象を指す。 具体的には、映像内にボートが映っているという強い視覚的な手がかりがある場合、モデルは音声入力には存在しない「魚が跳ねる音」や「人の話し声」を勝手に作り出してしまうことがある。このような問題は、モデルがモダリティ間の相互作用を適切に制御できていないという、より根本的な欠陥を露呈している。…
核心:何を提案したのか
本研究では、追加の学習やアノテーションを一切必要とせずにクロスモーダル・ハルシネーションを軽減する、新しいトレーニングフリーな手法「Modality-Adaptive Decoding(MAD)」を提案している。MADの核心的な革新性は、モデル自身にタスクにおけるモダリティの重要性を自己評価させ、その結果に基づいて対照的デコーディングの戦略を動的に適応させる点にある。具体的には、モデルに対して「この質問に答えるためにどのモダリティが必要か」というクエリを投げ、その予測確率からモダリティごとの重みを抽出する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related