ドリフトするMDPの幾何学:経路積分による安定性証明
現実世界の強化学習における非定常性を、報酬や遷移ダイナミクスが連続的に変化する微分可能なホモトピー経路としてモデル化し、最適ベルマン固定点の移動を幾何学的に追跡する新しい理論的枠組みを提案しています。
TL;DR(結論)
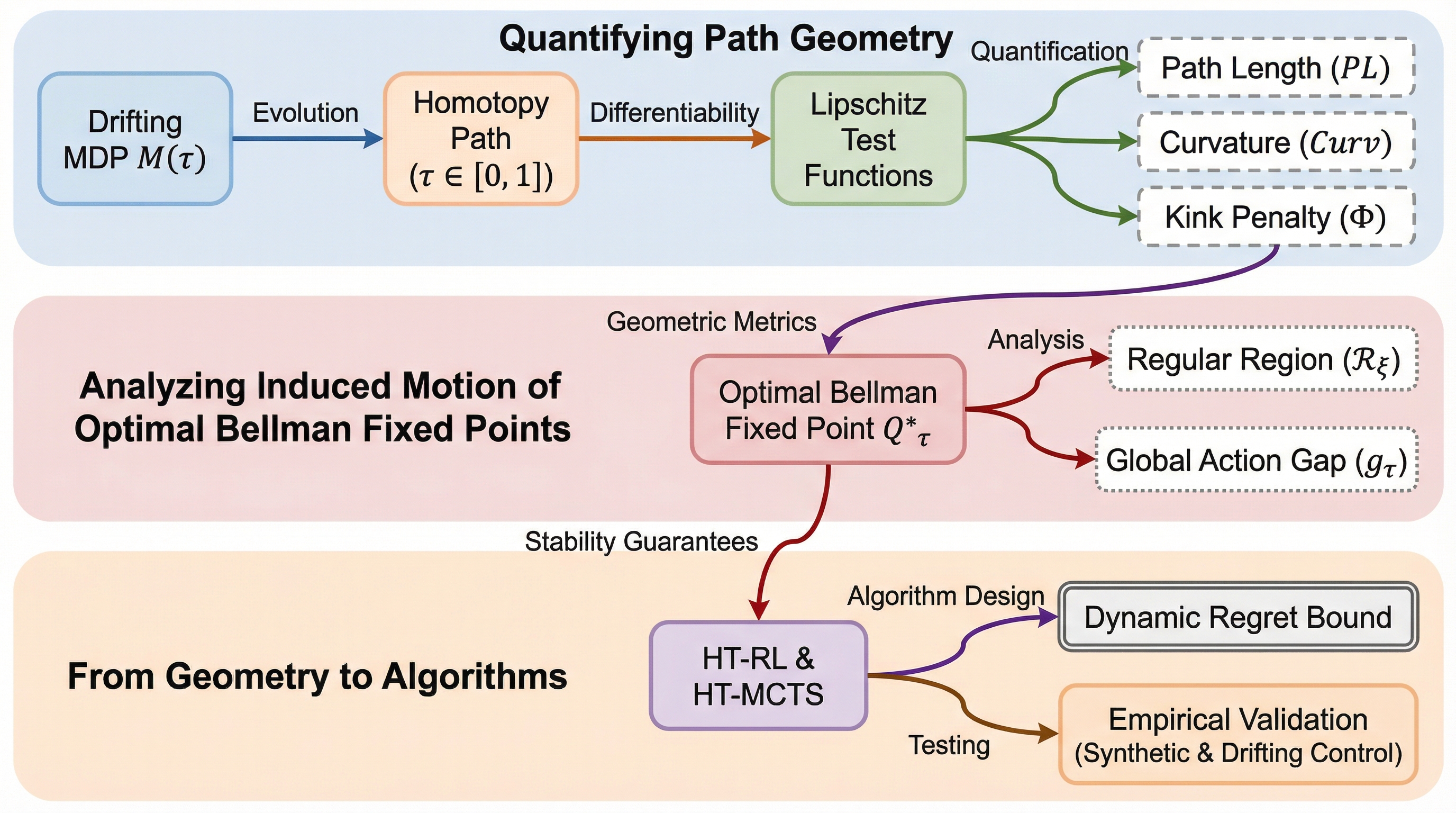
現実世界の強化学習における非定常性を、報酬や遷移ダイナミクスが連続的に変化する微分可能なホモトピー経路としてモデル化し、最適ベルマン固定点の移動を幾何学的に追跡する新しい理論的枠組みを提案しています。 環境の変化を「長さ(累積的なドリフト)」、「曲率(加速や振動)」、「キンク(最適行動の切り替わり)」という3つの幾何学的指標で定量化し、ソルバーに依存しない経路積分安定性境界と、局所的な安定性を保証するギャップセーフな実行可能領域を導出しました。 この理論に基づき、リプレイバッファから幾何学的指標をオンラインで推定して学習率や計画の強度を適応的に制御するHT-RLおよびHT-MCTSを開発し、特に振動や急激な切り替えが発生する環境において、従来の静的な手法を上回る追跡性能と動的リグレットの低減を実証しました。
なぜこの問題か
現実世界の強化学習において、環境が一定であることは稀であり、多くの場合で非定常性が深刻な問題となります。 例えば、ユーザーの嗜好の変化に伴って報酬関数がドリフトしたり、システムの更新や経年劣化によって遷移ダイナミクスが変化したりすることが一般的です。 このような環境下では、強化学習は単なる収束の問題ではなく、刻々と移動し続ける最適解を追いかける「追跡問題」へと変貌します。 しかし、従来の非定常強化学習の理論は、環境が「どれだけ」変化したかという非常に粗い尺度、例えば総変分や切り替え回数といったグローバルな予算に依存してきました。 これらの尺度は、環境が「どのように」局所的に変化しているかという詳細な構造を無視しており、実用的な指針を与えるには不十分でした。 特に、環境の変化率が変化する「加速」や「振動」といった現象は、価値推定を急速に陳腐化させ、追跡エラーを増大させる主要な要因となります。 また、複数の行動間で価値が拮抗している「ニアタイ(近接した選択肢)」の状態では、環境のわずかな変化が最適な行動を逆転させ、ポリシーの激しいチャタリングや不安定性を引き起こします。…
核心:何を提案したのか
本論文の核心は、非定常な割引MDPを、パラメータによって定義される微分可能なホモトピー経路としてモデル化した点にあります。 この経路に沿って移動する最適なベルマン固定点の挙動を解析するために、著者は「長さ(Path Length)」、「曲率(Curvature)」、「キンク(Kink)」という3つの幾何学的指標からなるシグネチャを導入しました。 「長さ」は報酬と遷移の累積的なドリフトを捉え、「曲率」はそのドリフト率の変化、すなわち加速や振動を測定します。 そして「キンク」は、最適な行動が切り替わる際の非滑らかな変化をペナルティとして定量化するものです。 これらの指標を用いることで、特定のアルゴリズムに依存しない「経路積分安定性境界」を証明しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related