トークンからブロックへ:分子生成におけるブロック拡散の視点
従来の分子言語モデルが直面していた「グラフ構造の把握不足」と「標的タンパク質への適応性欠如」を解決するため、SMILESを固定長のブロックに分割する「ソフトフラグメント」表現と、局所的な双方向拡散と自己回帰生成を融合させた世界初のブロック拡散モデル「SoftBD」を提案しました。
TL;DR(結論)
従来の分子言語モデルが直面していた「グラフ構造の把握不足」と「標的タンパク質への適応性欠如」を解決するため、SMILESを固定長のブロックに分割する「ソフトフラグメント」表現と、局所的な双方向拡散と自己回帰生成を融合させた世界初のブロック拡散モデル「SoftBD」を提案しました。 この手法は、化学的ルールに依存しない柔軟なブロック化によって複雑な構文を学習し、さらに薬理学的制約を判定するゲート付きモンテカルロ木探索(MCTS)を統合することで、特定の標的タンパク質に対して高い結合親和性を持つ分子を効率的に設計することを可能にしています。 大規模な実験の結果、SoftMolは化学的妥当性100%を達成しただけでなく、既存の最先端モデルと比較して結合親和性を9.7%向上させ、分子の多様性を2倍から3倍に高め、さらに推論速度を6.6倍に高速化するという、創薬プロセスを劇的に加速させる極めて優れた性能を実証しました。
なぜこの問題か
創薬のプロセスは、推定10の60乗個にも及ぶ膨大な化学空間の中から、特定の生物学的性質を持つ最適な分子を見つけ出すという、極めて困難な組み合わせ探索の問題として定義されます。この膨大な探索空間に対処するため、深層生成モデルを用いた新規分子設計(de novo design)の手法が近年盛んに研究されており、特に大規模なデータセットから化学的な構文や意味論を学習するGPTベースの分子言語モデル(MLM)が、その高い生成能力から注目を集めてきました。しかし、既存の分子言語モデルには、実用化を阻む二つの根本的な限界が存在しています。 第一に、分子は本質的に一次元の配列ではなく、原子間の複雑な相互作用によって構成される多次元的な化学グラフとしての性質を持っています。従来のモデルは「次のトークンを予測する」という一方向の自己回帰的な処理に依存しているため、局所的な化学的文脈や、分子の部分構造内における原子同士の双方向的な依存関係を十分に捉えることができません。これにより、生成された分子が化学的に不自然であったり、複雑な環構造を正しく構築できなかったりするという課題がありました。…
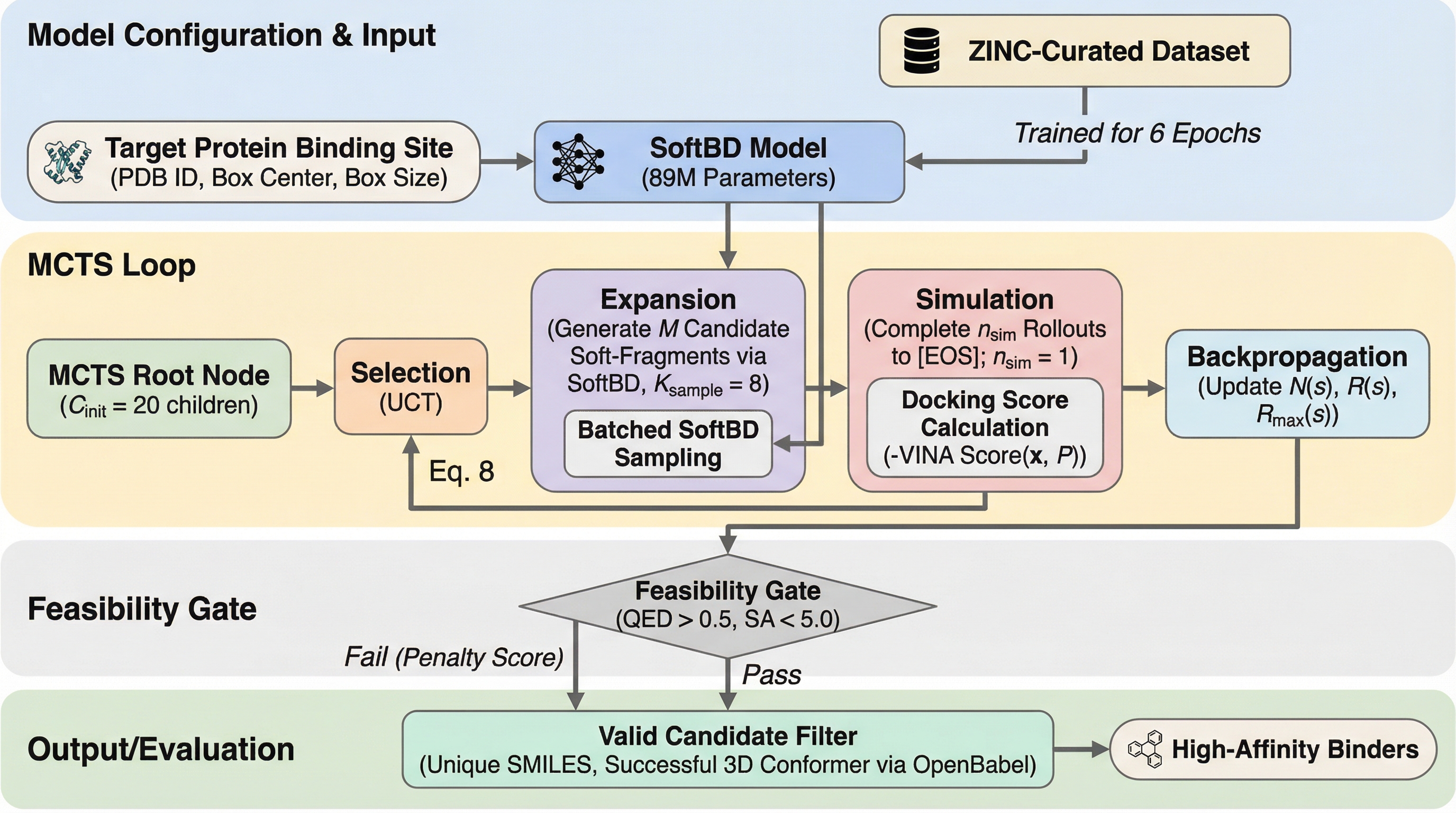
核心:何を提案したのか
本研究では、分子の表現方法、モデルのアーキテクチャ、そして探索戦略を統合的に設計した新しいフレームワーク「SoftMol」を提案しました。SoftMolの核心となるのは、SMILES配列を化学的なルールに依存せずに固定長のブロックに分割する「ソフトフラグメント」という革新的な表現手法です。これは従来のルールベースの断片化(SAFEなど)とは異なり、計算機的に決定論的な分割を行うことで、拡散モデルにネイティブに対応した形式を提供します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related