FIRE-Bench: 科学的知見の再発見を通じたエージェント評価ベンチマーク
大規模言語モデル(LLM)を基盤とした自律型エージェントは、文献の調査から仮説の立案、実験の実施、データ分析に至る科学的研究の全工程を自動化し、発見の速度を劇的に向上させることが期待されています。
TL;DR(結論)
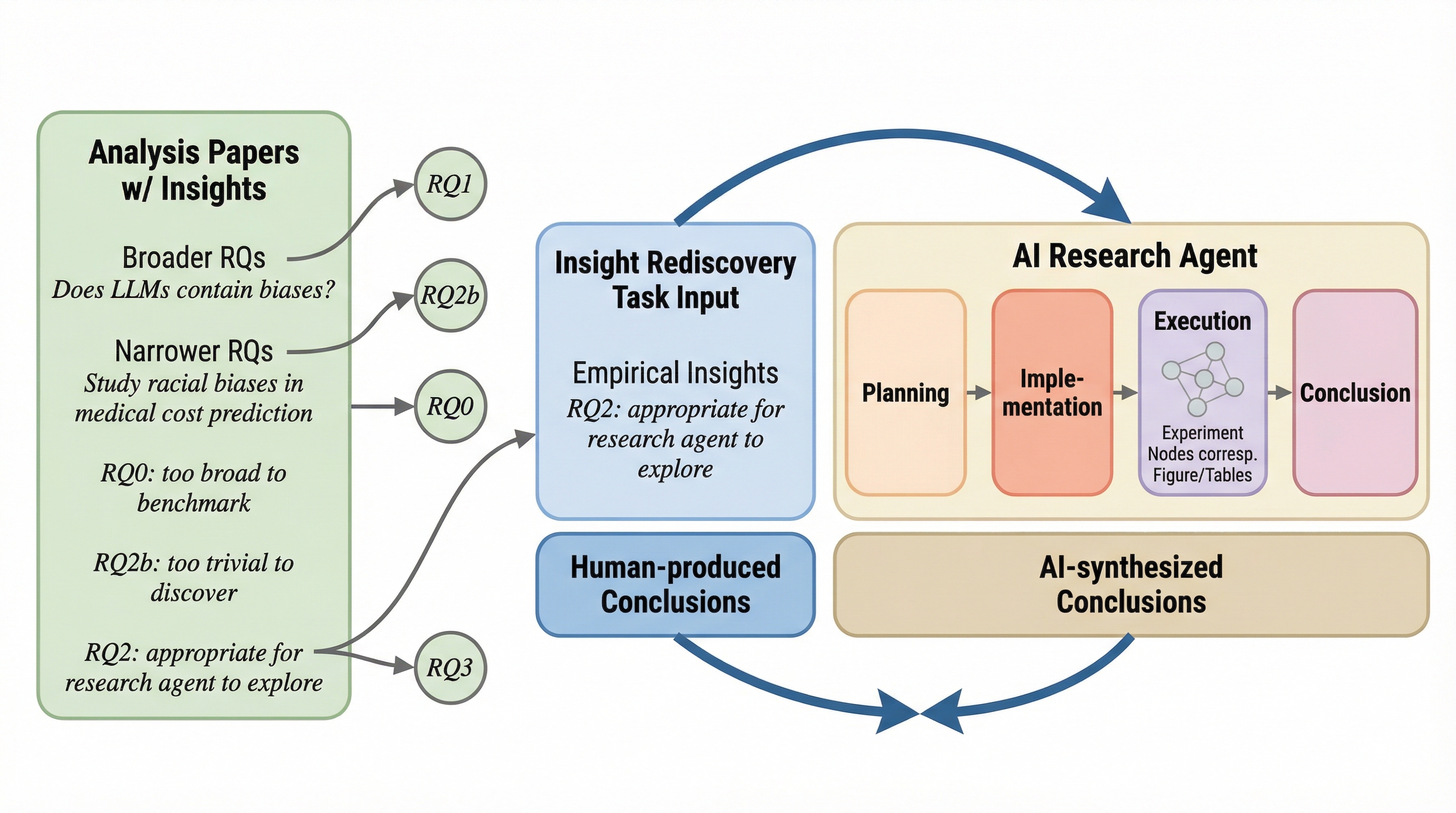
大規模言語モデル(LLM)を基盤とした自律型エージェントは、文献の調査から仮説の立案、実験の実施、データ分析に至る科学的研究の全工程を自動化し、発見の速度を劇的に向上させることが期待されています。しかし、これらのエージェントが生成した研究成果の科学的正当性を、大規模かつ客観的に検証するための信頼できる評価手法が不足していることが、分野の進展を妨げる大きな障壁となっていました。 本研究では、最新の機械学習分野で既に査読を通過し確立されている知見をエージェントに自律的に「再発見」させることで、その研究遂行能力を厳密に測定する新しいベンチマーク「FIRE-Bench」を提案しました。この枠組みでは、エージェントに具体的な実験手順を伏せた状態でハイレベルな研究課題のみを与え、自ら実験を設計し、コードを実装・実行して、得られた証拠から妥当な結論を導き出せるかを、30件のタスクを通じて多角的に評価します。 検証の結果、最新の高機能エージェントであっても、科学的知見を正確に再発見できた割合を示すF1スコアは50未満という低い水準にとどまり、さらに同じ課題に対しても実行ごとに結果が大きく変動する不安定さが確認されました。特に、研究計画の策定や実験結果に基づく論理的な推論において失敗が集中しており、現在のAI技術が真の意味で自律的な科学者として機能するためには、単なるコーディング能力を超えた高度な推論能力の強化が不可欠であることが明らかになりました。
なぜこの問題か
大規模言語モデル(LLM)を基盤とした自律型エージェントは、科学的な発見のプロセスをエンドツーエンドで加速させる可能性を秘めています。これらの「AI研究者」は、文献の合成、仮説の生成、コーディング、実験の実施、そしてデータ分析といった、研究ライフサイクルの個別の段階を自動化する能力を日々向上させています。しかし、これらのエージェントが真に検証可能な科学的発見を行う能力を持っているかどうかを、厳密かつ大規模に評価することは依然として中心的な課題となっています。既存の評価ベンチマークには、主に2つの大きなトレードオフが存在しており、評価の信頼性や範囲に限界がありました。 一つ目のパラダイムは、エージェントに完全な研究論文を作成させ、その出力をLLMを審判員として評価させる手法ですが、これは専門家による評価の代用としては不十分な場合があります。LLMによる評価は、科学的な妥当性よりも文章の流暢さや形式に左右されるリスクがあり、大規模な検証において信頼性を担保することが困難です。二つ目のパラダイムは、リーダーボード上でのモデルの精度向上など、単一の性能指標に焦点を当てた機械学習タスクに限定する手法です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related