LLMはロケット科学ができるか?GTOC 12を用いた複雑な推論の限界の探究
本研究は、大規模言語モデル(LLM)が「ロケット科学のワールドカップ」と称される極めて複雑な宇宙力学競技会「GTOC 12」において、自律的なミッション設計が可能かを検証しました。 最新の推論モデルは過去2年間で戦略的妥当性のスコアを9.3から17.
TL;DR(結論)
本研究は、大規模言語モデル(LLM)が「ロケット科学のワールドカップ」と称される極めて複雑な宇宙力学競技会「GTOC 12」において、自律的なミッション設計が可能かを検証しました。 最新の推論モデルは過去2年間で戦略的妥当性のスコアを9.3から17.2へと倍増させており、小惑星の選別や目的関数の設定といった概念的なミッション構築において顕著な進歩を示しています。 しかし、物理単位の不整合や境界条件の誤りといった実装上の致命的な障壁により、有効な数値解の生成には至っておらず、現状のLLMは自律的なエンジニアではなく専門家を補助する「ドメイン促進者」の段階に留まっています。
なぜこの問題か
大規模言語モデル(LLM)は、一般的なコード生成や論理推論において驚異的な能力を示していますが、高次元で物理的な制約が極めて厳しい環境における自律的な多段階計画の立案能力については、依然として未解明な部分が多く残されています。既存のAI評価ベンチマークの多くは、LLMの急速な進歩によって容易に突破されるようになっており、現実世界の複雑なエンジニアリング問題を解決するために必要な思考の深さを十分に測定できていません。そこで本研究では、世界最高峰の航空宇宙エンジニアや数学者がその知恵を競い合う「Global Trajectory Optimization Competition (GTOC)」の第12回大会を評価対象として選定しました。この競技は、2005年に欧州宇宙機関(ESA)によって創設されて以来、ほぼ不可能に近い軌道力学の課題を約4週間という短期間で解くことが求められる、伝統と権威のある大会です。…
核心:何を提案したのか
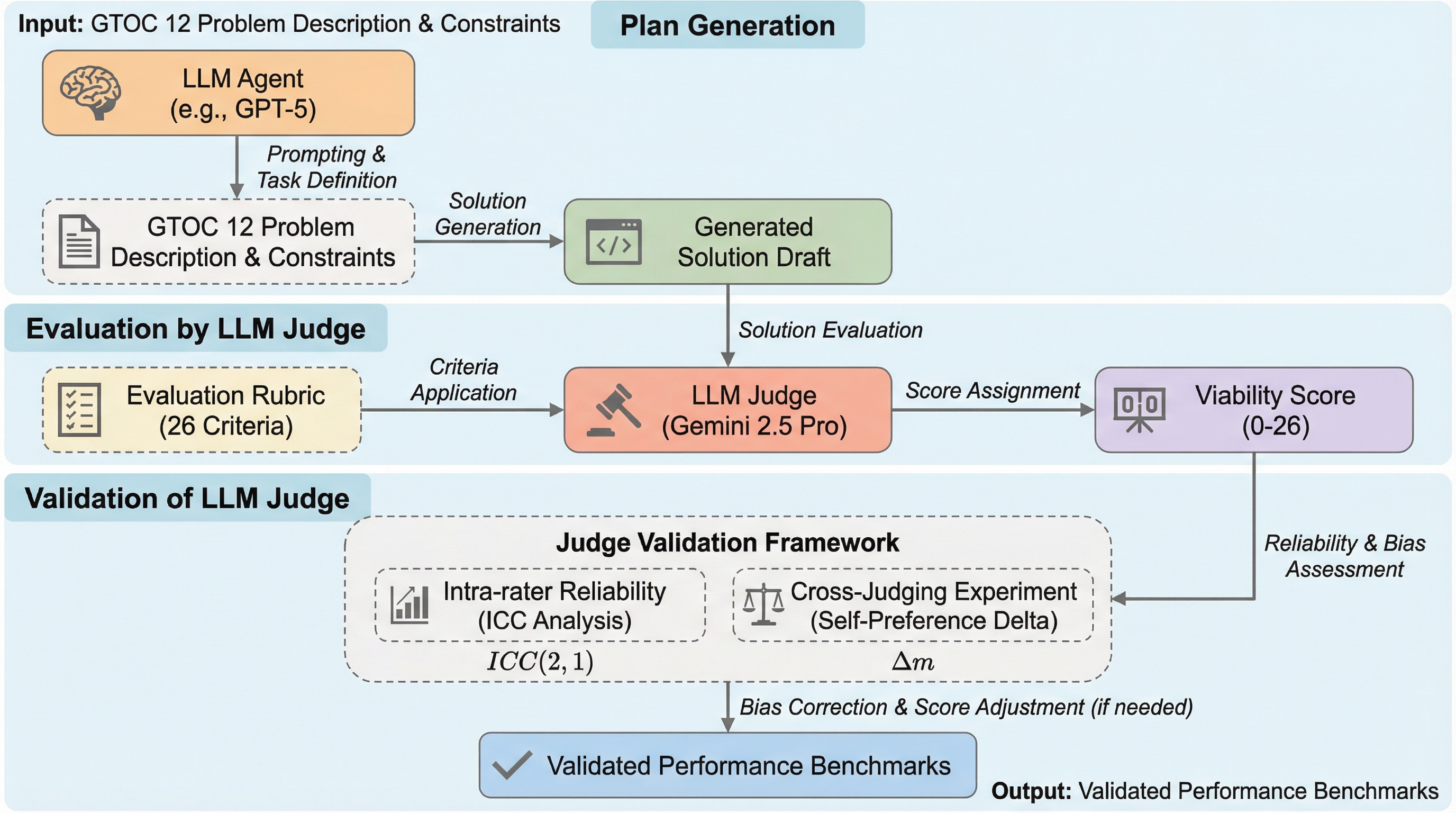
本研究では、AIエージェントの能力を厳密に評価するために、機械学習エンジニアリングのベンチマークである「MLE-Bench」の枠組みを宇宙力学の領域に初めて適応させました。MLE-Benchは本来、Kaggleのようなデータサイエンス競技において、データの準備からモデルの訓練、ハイパーパラメータの調整までを自律的に行う能力を測るものですが、本研究ではこれを数値最適化と戦略立案が主眼となるGTOC 12の課題に合わせて再構築しました。この環境下で、機械学習のタスクを自動化するエージェント・アーキテクチャである「AIDE (Agent for Iterative Data-science Exploration)」をデプロイしました。AIDEは、単一の線形な試行ではなく、解の候補をツリー構造で探索し、ドラフトの作成、実行、デバッグ、洗練を系統的に繰り返す「最良優先探索」アプローチを採用しているのが特徴です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related