マルコフ決定問題に対する制御ベルマン残差最小化の解析
強化学習の標準的な動的計画法は関数近似下で収縮性を失い収束が不安定になる課題があるが、本研究はベルマン残差最小化を政策最適化(制御タスク)へ拡張し、非凸・非平滑な目的関数が持つ区分的二次構造や局所リプシッツ連続性を解明することで、関数近似を用いても安定して解を探索できる理論的基盤を確立した。
TL;DR(結論)
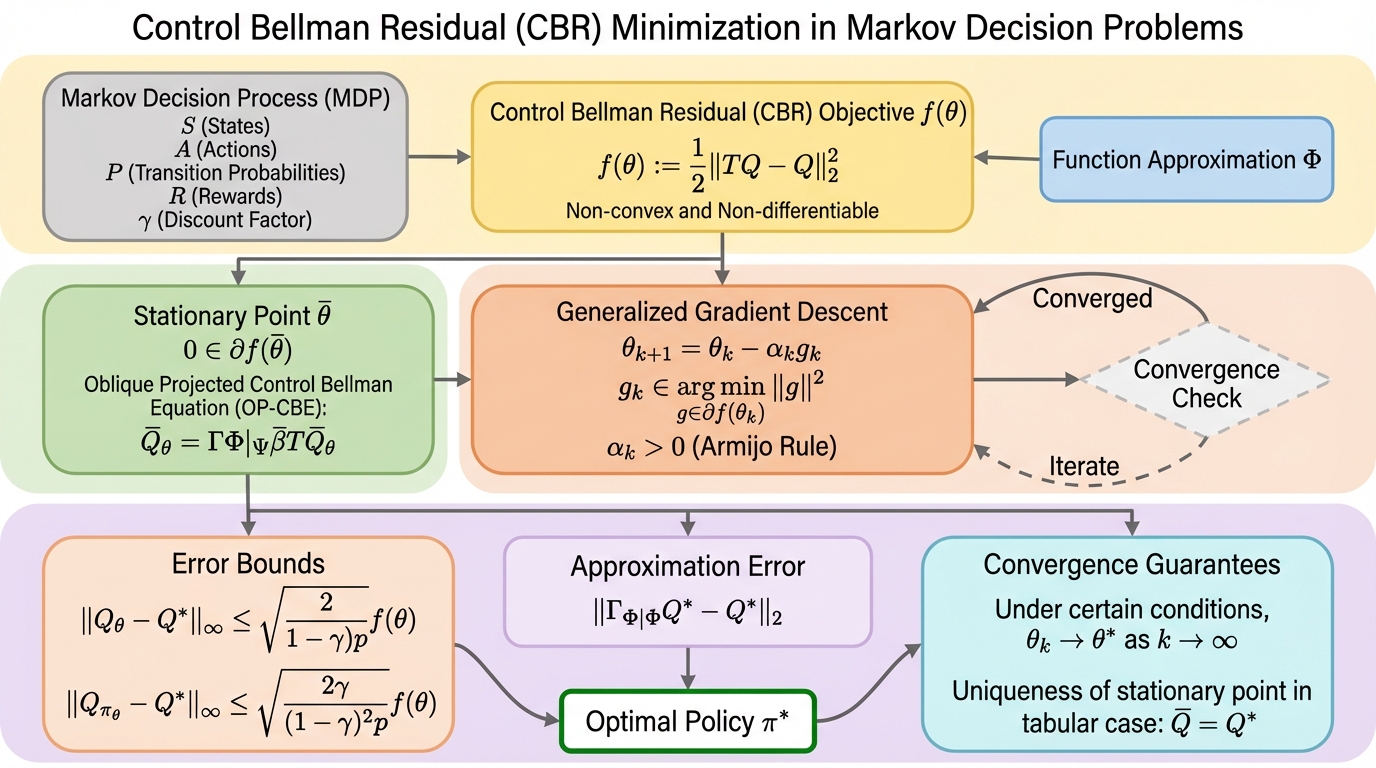
強化学習の標準的な動的計画法は関数近似下で収縮性を失い収束が不安定になる課題があるが、本研究はベルマン残差最小化を政策最適化(制御タスク)へ拡張し、非凸・非平滑な目的関数が持つ区分的二次構造や局所リプシッツ連続性を解明することで、関数近似を用いても安定して解を探索できる理論的基盤を確立した。 提案された制御ベルマン残差(CBR)の停留点は、政策評価の理論を拡張した「斜め射影制御ベルマン方程式(OP-CBE)」の解として特徴付けられ、クラーク劣微分を用いた一般化勾配降下法により、非凸な構造下でも停留点への収束が保証されるとともに、ソフトマックス演算子を導入した微分可能なソフト制御ベルマン残差(SCBR)による効率的な最適化手法も提示された。 理論的検証により、表形式の設定では目的関数の停留点が唯一の最適解に一致することを証明し、線形関数近似下においても得られる近似解と真の最適価値関数および最適政策との間の誤差境界を数学的に導出することで、従来の射影価値反復法では困難だった収束性と精度の保証をベルマン残差最小化の枠組みで実現した。
なぜこの問題か
無限ホライズンの割引マルコフ決定問題(MDP)を解決するための最も一般的なアプローチは、価値反復法に代表される動的計画法である。しかし、大規模な状態空間を扱うために線形関数近似などの手法を導入すると、ベルマン作用素が持つ「収縮性」という重要な数学的性質が失われる可能性がある。収縮性が失われると、アルゴリズムが解に収束する保証がなくなり、学習が不安定化したり発散したりするという深刻な課題が生じる。これに対し、ベルマン残差最小化(BRM)は、ベルマン方程式の誤差の二乗和を直接最小化する手法であり、関数近似下でも安定した収束解を見つけやすいという利点がある。 それにもかかわらず、ベルマン残差最小化はこれまで動的計画法に比べて注目されてこなかった。その主な理由は、実用上の計算効率が劣ることや、モデルフリーの強化学習設定への拡張が難しいと考えられてきたためである。特に、既存の研究の多くは「政策評価(与えられた政策の価値を推定するタスク)」に集中しており、「政策最適化(最適な政策を見つける制御タスク)」におけるベルマン残差の性質は十分に解明されていなかった。…
核心:何を提案したのか
本論文の核心的な提案は、政策最適化のための「制御ベルマン残差(CBR)」最小化という新しい理論的枠組みの構築である。まず、線形関数近似を用いたQ関数のパラメータ化を行い、制御ベルマン作用素によって更新されたQ関数と現在の近似Q関数の差の二乗ノルムとして目的関数を定義した。この目的関数は、ベルマン方程式を解くための最も直感的な指標であるが、最大化演算子の存在によって従来の最適化手法がそのままでは適用できない。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related