「これは何語ですか?」をトークナイザに聞く:UniLID
高資源言語ではほぼ解けたと見なされがちな言語識別でも、低資源言語や近縁言語・方言の区別では脆さが残るため、トークナイズの確率的な枠組みそのものを手掛かりにして堅牢性と効率を両立させます。 / 共通のトークナイザ語彙の上で言語ごとのユニグラム分布を学習しつつ、文字列の分割は言語に依存して変わり得る潜在変数として扱い、各言語で最も起こりやすい分割の確率を比べてベイズ則で言語を選びます。 / 標準ベンチマークで既存手法と競争的な性能を保ちながら、各言語5件のラベル付き例でも正解率が70%を超え、方言識別でもマクロF1が0.53から0.72へ伸びるなど、少量データや細粒度設定での改善が示されています。
TL;DR(結論)
- 高資源言語ではほぼ解けたと見なされがちな言語識別でも、低資源言語や近縁言語・方言の区別では脆さが残るため、トークナイズの確率的な枠組みそのものを手掛かりにして堅牢性と効率を両立させます。
- 共通のトークナイザ語彙の上で言語ごとのユニグラム分布を学習しつつ、文字列の分割は言語に依存して変わり得る潜在変数として扱い、各言語で最も起こりやすい分割の確率を比べてベイズ則で言語を選びます。
- 標準ベンチマークで既存手法と競争的な性能を保ちながら、各言語5件のラベル付き例でも正解率が70%を超え、方言識別でもマクロF1が0.53から0.72へ伸びるなど、少量データや細粒度設定での改善が示されています。
なぜこの問題か
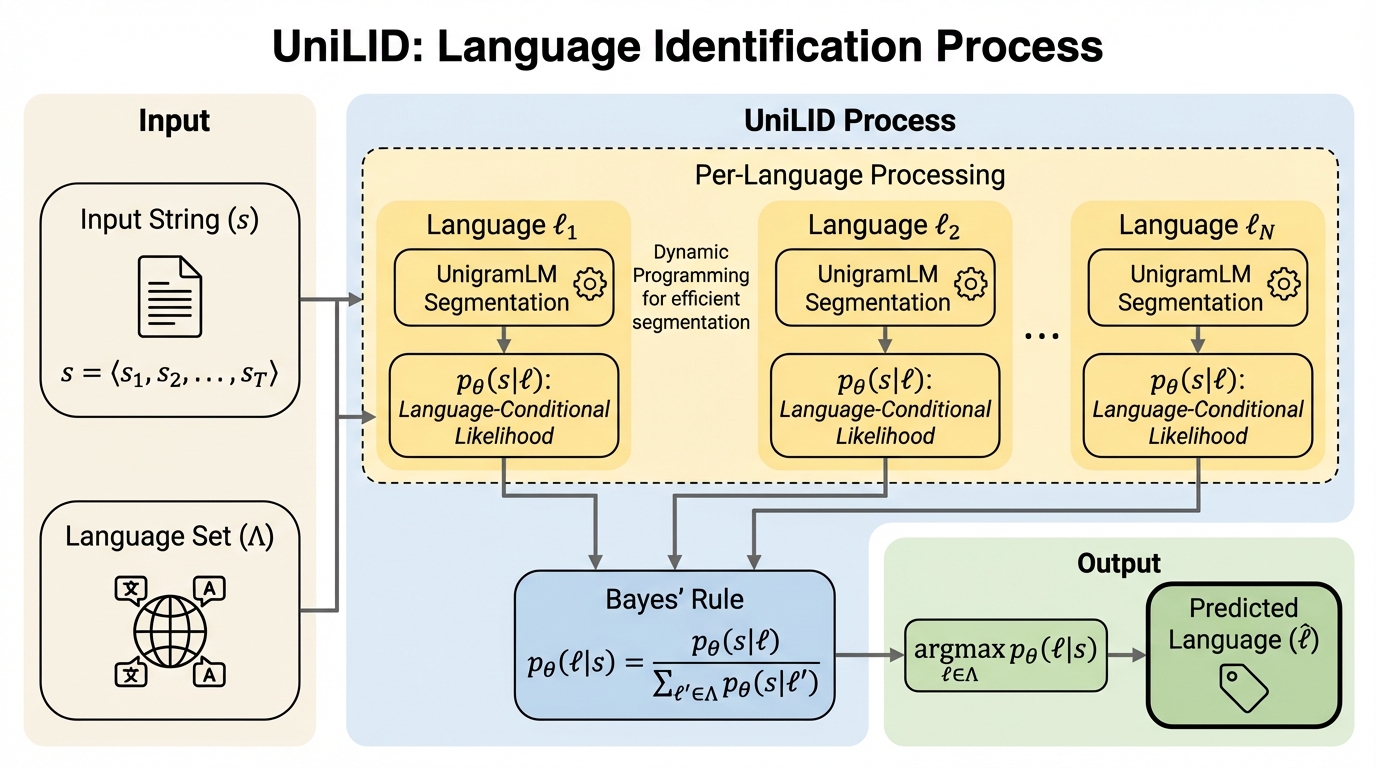
言語識別(LID)は、多言語の自然言語処理パイプラインで基礎になる機能です。論文では、コーパス整備、学習データの構成分析、大規模な多言語言語モデルの言語横断評価を支える用途として位置づけています。高資源言語や中資源言語では、既存システムがほぼ完璧に近い性能を示すことが多く、長い間「解けた課題」と捉えられてきた経緯も示されています。 一方で、低資源言語、互いに近い言語ペア、さらに方言のような細粒度の変種に対しては、既存手法が依然として不安定になりやすいと述べられています。加えて、最先端の言語モデルであっても、あまり一般的ではない言語を一貫して同定できないという指摘が挙げられています。低資源言語ではデータ量そのものが不足しやすく、存在するデータにも高資源言語の断片やHTMLの混入といったノイズが含まれ得るため、推定が難しくなります。 さらに、整備されたテキストで訓練されたモデルが、ソーシャルメディアのような非形式的な入力、あるいは翻字された表記に弱いというドメインシフトの問題も明確にされています。…
核心:何を提案したのか
本研究は、UniLIDという言語識別手法を提案しています。考え方の中核は、UnigramLMのトークナイズを「確率モデル」として捉える枠組みと、古典的なベイズの意思決定則を組み合わせる点にあります。従来のLIDでは、文字n-gramにもとづく生成モデル、特徴量にもとづく識別モデル、ニューラル分類器などが広く使われてきましたが、低資源や近縁言語・方言では十分に安定しないことが背景にあります。 UniLIDの特徴は、「語彙は共有し、分布は言語ごとに持つ」という分解にあります。具体的には、ある基礎トークナイザが持つ固定語彙を全言語で共通に用意し、その語彙上で各言語に条件づくユニグラム分布(トークンの出現確率)を別々に学習します。同時に、文字列をどのトークン列に分割するかというセグメンテーションは、前処理で一意に固定するのではなく、言語ごとに最も起こりやすい分割が異なり得る現象として扱います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related