ViTaB-A:マルチモーダル大規模言語モデルにおける「表の根拠提示(行・列・セル引用)」を評価する。
表(Markdown、JSON、画像)に対するマルチモーダル大規模言語モデルは、質問への最終回答が中程度に正しい場合があっても、その答えを支える行・列・セルを正確に指し示す能力には大きな不足があり、特にJSONでは根拠提示がほぼ偶然に近い水準まで落ちます。
TL;DR(結論)
- 表(Markdown、JSON、画像)に対するマルチモーダル大規模言語モデルは、質問への最終回答が中程度に正しい場合があっても、その答えを支える行・列・セルを正確に指し示す能力には大きな不足があり、特にJSONでは根拠提示がほぼ偶然に近い水準まで落ちます。
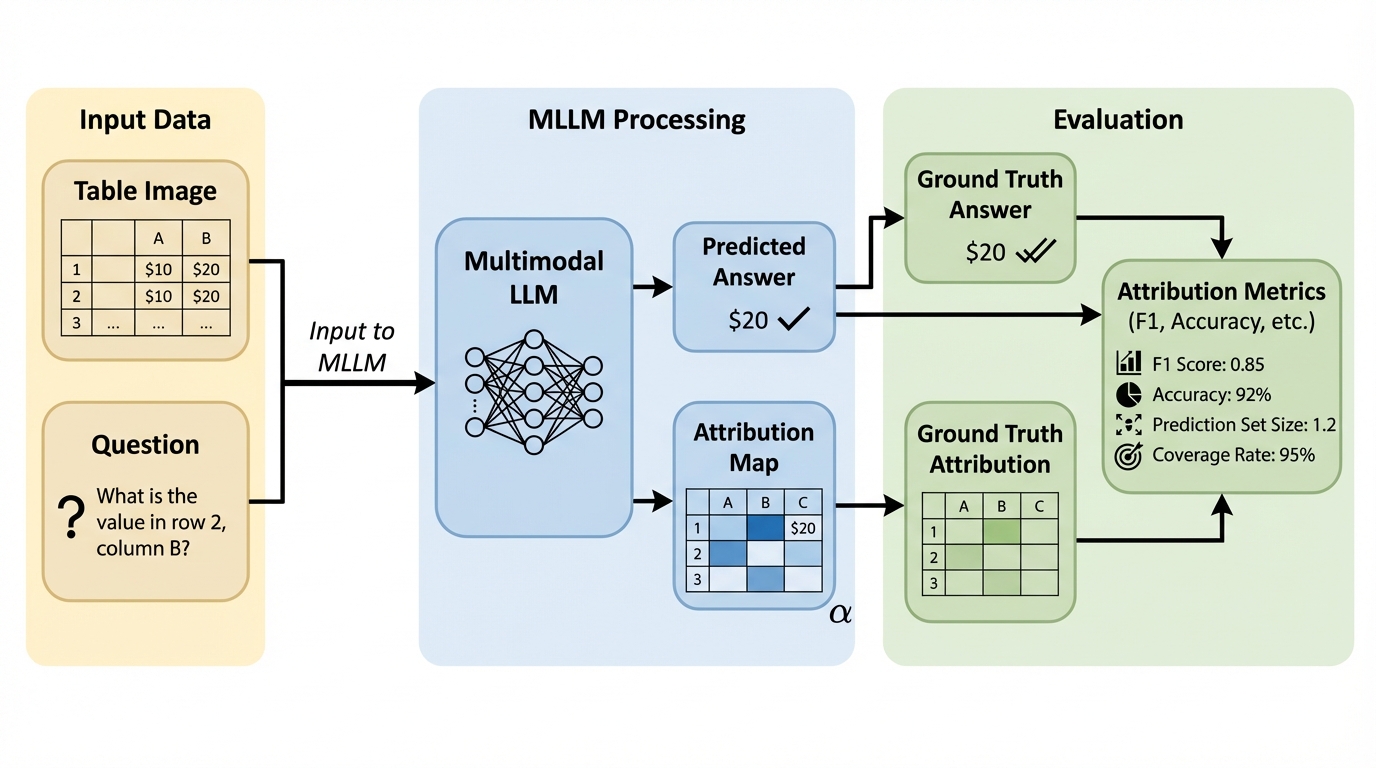
- ViTaB-Aは、質問と表に加えて正解の答え自体も入力として与え、生成のうまさではなく「答えの根拠が表のどこにあるか」をセル座標で引用させることで、表形式(Markdown、JSON、レンダリング画像)とプロンプト(ゼロショット、フューショット、CoT)による違いを体系的に比べます。
- 実験では、質問応答の正確性が概ね48〜55%程度で推移する一方、根拠提示の正確性は大幅に低く、画像で30%台、JSONでは平均で1%未満にまで低下し、透明性や追跡可能性が必要な用途で現状のモデルをそのまま使う難しさが示されます。
なぜこの問題か
マルチモーダル大規模言語モデルは、表に書かれた値を読み取り、比較し、要約する「汎用データアシスタント」として使われる場面が増えています。入力となる表の形式も、Markdownの表、JSONのような構造化テキスト、文書画像として埋め込まれた表など多様です。しかし現場では、答えが当たっているかどうかだけでは足りないことが多いです。たとえば、ある年に収益が増えたという主張が出たとき、利用者が次に知りたいのは「表のどの行のどの列がその主張を支えているか」です。ここが確認できなければ、答えが偶然当たったのか、正しい根拠に接地しているのかを点検できません。 問題は、現在のシステムではこの「根拠の場所を指す」工程がしばしば信頼できない点にあります。本文抜粋が述べるとおり、モデルが正しい答えを返しているのに、根拠として示すセルがずれてしまう状況が起きます。こうなると、利用者は検証の出発点を失い、誤った意思決定に結びつくリスクが高まります。特に、監査可能性やトレーサビリティが要求される金融、医療、法律のような領域では、「もっともらしい答え」ではなく、特定のデータ項目にひもづく説明が必要になります。…
核心:何を提案したのか
本研究が中心に据えるのは、構造化データに対するアトリビューション/引用、すなわち「答えを支える表の行・列を特定できるか」という能力です。提案の核は、ViTaB-Aというベンチマーク枠組みの提示にあります。ViTaB-Aは、Markdown、JSON、レンダリング画像という複数の表現形式を横断し、同じ種類の課題を同じ評価軸で点検できるように設計されています。 特徴的なのは、各インスタンスが「自然言語の質問」「表」「正解の答え」から構成され、モデルには答えを生成させるのではなく、答えの根拠となるセル集合を行・列のインデックスで返させる点です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related