Hindsight Quality Prediction:人手ポストエディット翻訳の多候補品質予測を見直す
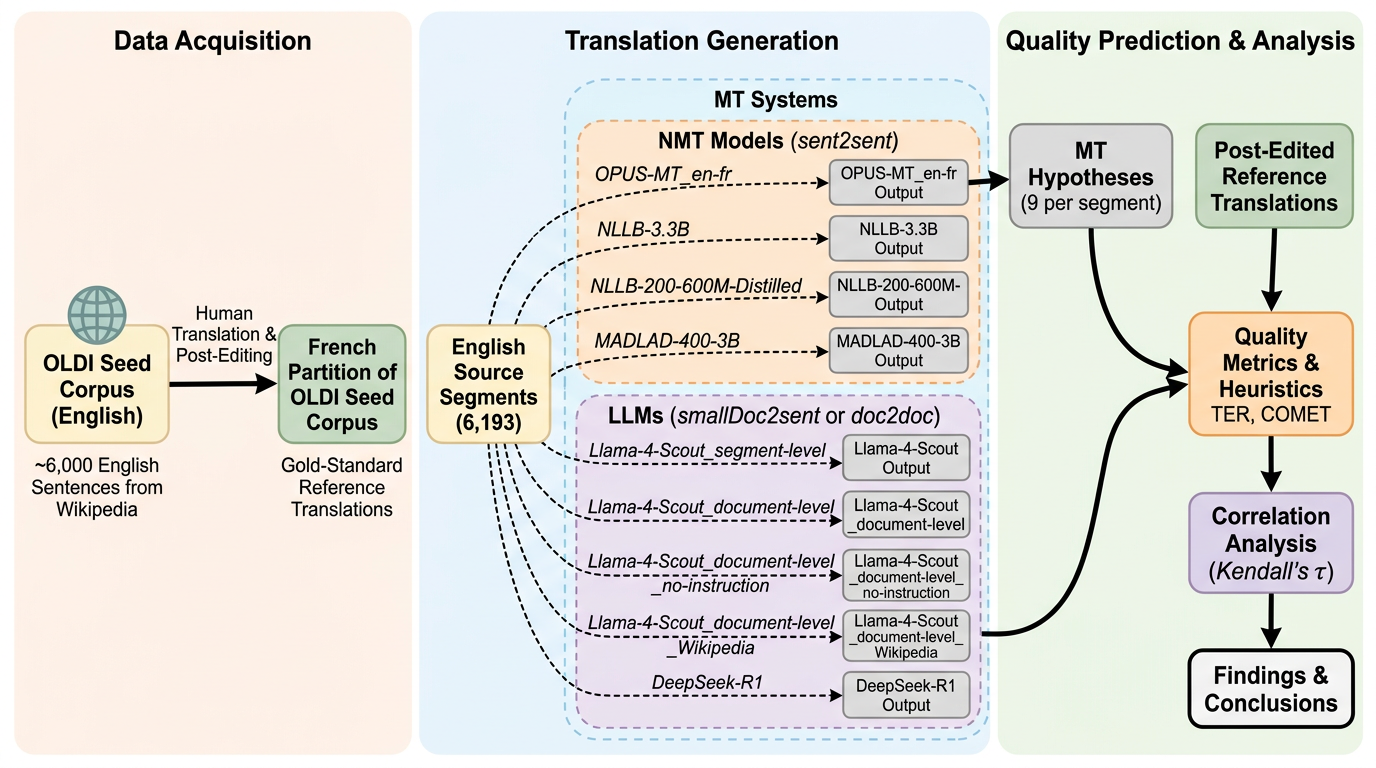
本研究は、実際の機械翻訳ポストエディット案件から得られた 6,000 超の英語文と 9 個の翻訳候補を使い、翻訳品質予測の二つの系統、すなわち「原文側の難しさ予測」と「候補文側の品質推定」を同じ土台で見直したものです。 Kendall の順位相関で TER と COMET の両方を参照すると、原文側指標の当たり方は評価軸によって大きく変わり、候補文側の QE 指標も従来型 NMT には比較的合う一方、汎用 LLM の出力にはそのままでは合いにくいことが分かりました。 文書後半ほど訳質が落ちる document-level LLM の位置バイアスは統計的には確認されましたが、実務影響は小さく、むしろ重要なのは「どの品質概念を測りたいのか」を TER と COMET の違いまで含めて明示することだと示しています。
TL;DR(結論)
- 本研究は、実際の機械翻訳ポストエディット案件から得られた 6,000 超の英語文と 9 個の翻訳候補を使い、翻訳品質予測の二つの系統、すなわち「原文側の難しさ予測」と「候補文側の品質推定」を同じ土台で見直したものです。
- Kendall の順位相関で TER と COMET の両方を参照すると、原文側指標の当たり方は評価軸によって大きく変わり、候補文側の QE 指標も従来型 NMT には比較的合う一方、汎用 LLM の出力にはそのままでは合いにくいことが分かりました。
- 文書後半ほど訳質が落ちる document-level LLM の位置バイアスは統計的には確認されましたが、実務影響は小さく、むしろ重要なのは「どの品質概念を測りたいのか」を TER と COMET の違いまで含めて明示することだと示しています。
なぜこの問題か
機械翻訳では、最終出力そのものだけでなく、「どの文が難しいか」「どの候補を採るべきか」を予測する仕組みが現場の負荷を左右します。原文を見た時点で難しさが分かれば、あらかじめ人手を厚く配分できますし、複数候補の良し悪しを参照なしで比べられれば、後段の選別や自動化も進めやすくなります。
核心:何を提案したのか
提案の中心は、新しい単独モデルではありません。核は、実際のポストエディット案件から得られた multi-candidate データセットを使い、品質予測の二つのパラダイムを同じ条件で比較し直す「hindsight experiment」です。各英語原文に対して、従来型 NMT と先進的な LLM を含む 9 つの翻訳候補があり、それらすべてを最終的な人手ポストエディット参照と照合できるようにしています。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related