DySCO:長文脈で散る注意を、検索向きヘッドでその場ごとに締め直す
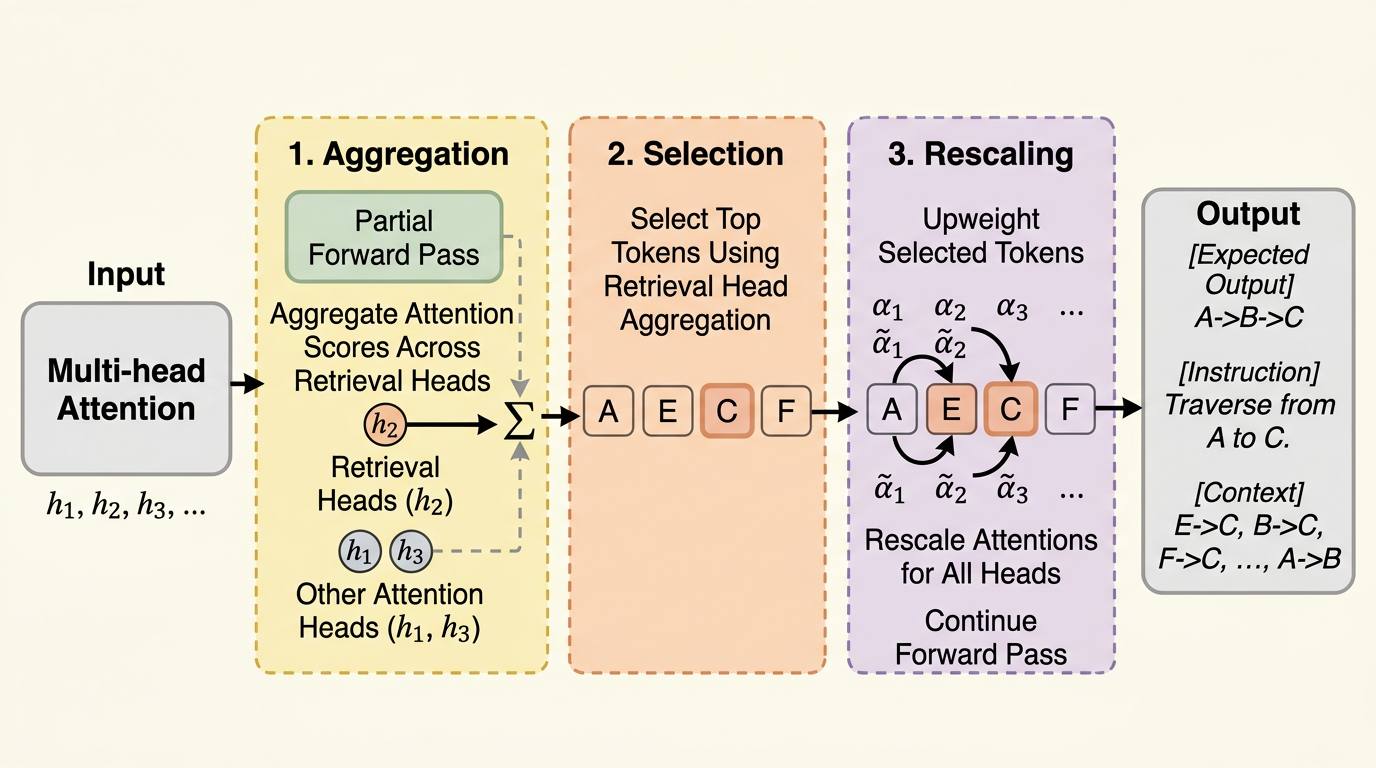
DySCO は、長文脈推論で精度が落ちる原因を「関連箇所への注意が生成途中で薄まること」と捉え、retrieval heads を使ってその時点で重要なトークンを見つけ、全ヘッドの注意を動的に増幅する推論時アルゴリズムです。 学習不要で既存モデルにそのまま適用でき、Qwen3-8B では 128K 文脈の MRCR と LongBenchV2 で YaRN 単独比最大 25% 相対改善、追加計算はおおむね 4% 程度に収まっています。 重要なのは、一律に attention を鋭くするのではなく、「今この生成ステップで必要な箇所だけ」を選んで強める点で、長文脈の精度改善を retrieval / compression とは別の軸で成立させたことです。
論文図解
TL;DR(結論)
- DySCO は、長文脈推論で精度が落ちる原因を「関連箇所への注意が生成途中で薄まること」と捉え、retrieval heads を使ってその時点で重要なトークンを見つけ、全ヘッドの注意を動的に増幅する推論時アルゴリズムです。
- 学習不要で既存モデルにそのまま適用でき、Qwen3-8B では 128K 文脈の MRCR と LongBenchV2 で YaRN 単独比最大 25% 相対改善、追加計算はおおむね 4% 程度に収まっています。
- 重要なのは、一律に attention を鋭くするのではなく、「今この生成ステップで必要な箇所だけ」を選んで強める点で、長文脈の精度改善を retrieval / compression とは別の軸で成立させたことです。
なぜこの問題か
長文脈対応の改善策は、これまで大きく二つに寄ってきました。ひとつは、そもそも見せる文脈を削る方法です。RAG、prompt compression、KV eviction などがこれに当たります。もうひとつは、スケーリングや拡張機構で「もっと長く読めるようにする」方法です。ところが前者は情報を削る副作用があり、後者は文脈長の仕様を伸ばしても、実際の reasoning 品質が伸びるとは限りません。
核心:何を提案したのか
DySCO の核心は、長文脈推論の失敗を「重要箇所への attention が十分集まらないこと」とみなし、その補正を decoding 時にだけ行う点にあります。学習や追加微調整は不要で、既存の off-the-shelf な LM にそのまま被せられる。ここがまず実用的です。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related