DDTSR:音声対話の待ち時間を「談話接続」と並列処理で前倒しする
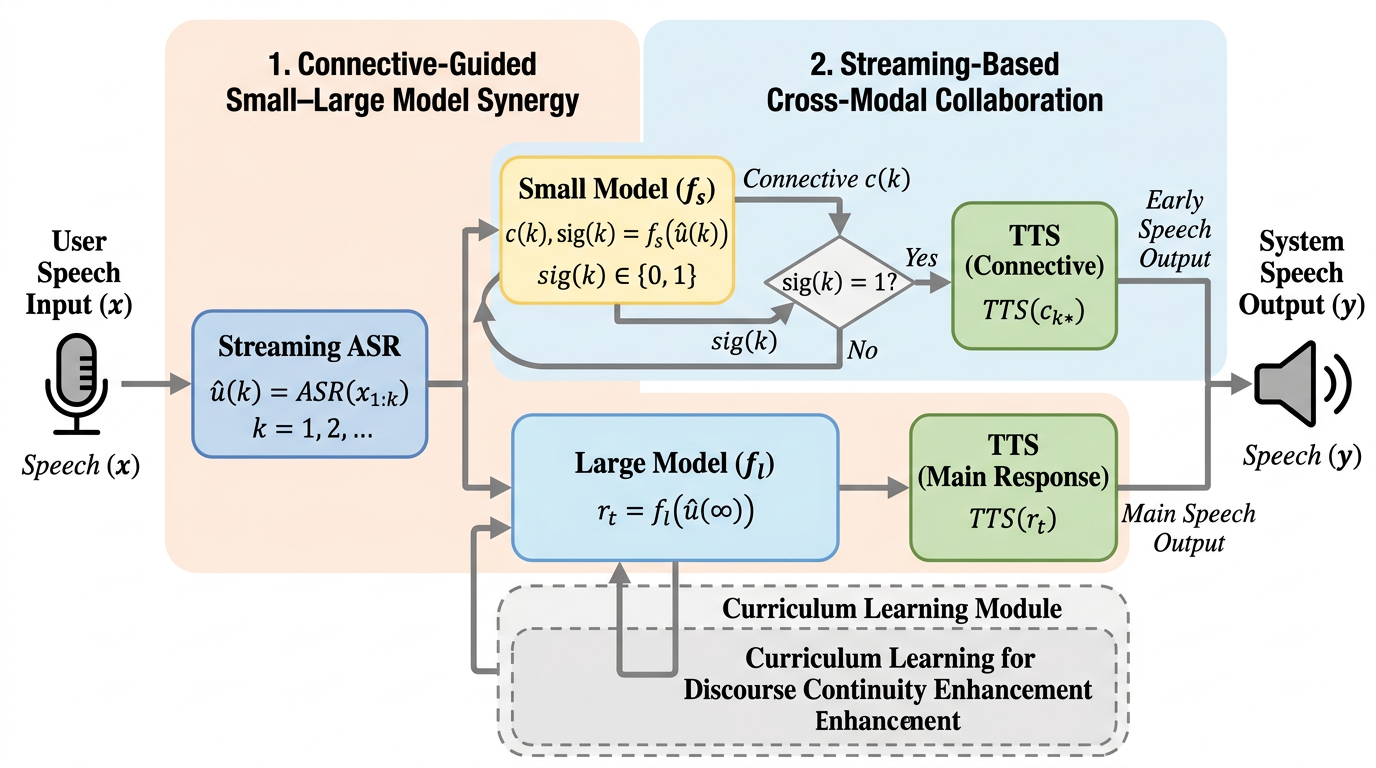
DDTSR は、音声対話で最も不快な「考えてから話し始める待ち時間」を、軽量モデルが安全なつなぎ表現を先に出し、大きなモデルが本体を並列生成する二段構えで短縮する手法です。 重要なのは単なる高速化ではなく、ユーザーが体感する待ち時間を分解し、知覚遅延と反応遅延の両方を別々に削っていることです。SD-Eval では待ち時間を 1003ms から 548ms、条件によっては 515ms まで下げています。 しかも一貫性・談話のまとまり・音声自然性は大きく崩しておらず、既存の ASR や TTS を総入れ替えせずに会話体験だけを改善できる点が、研究としても実装としても強いです。
論文図解
TL;DR(結論)
- DDTSR は、音声対話で最も不快な「考えてから話し始める待ち時間」を、軽量モデルが安全なつなぎ表現を先に出し、大きなモデルが本体を並列生成する二段構えで短縮する手法です。
- 重要なのは単なる高速化ではなく、ユーザーが体感する待ち時間を分解し、知覚遅延と反応遅延の両方を別々に削っていることです。SD-Eval では待ち時間を 1003ms から 548ms、条件によっては 515ms まで下げています。
- しかも一貫性・談話のまとまり・音声自然性は大きく崩しておらず、既存の ASR や TTS を総入れ替えせずに会話体験だけを改善できる点が、研究としても実装としても強いです。
なぜこの問題か
音声対話の遅さは、単に GPU が遅いからではありません。遅延は少なくとも三つに分かれます。ユーザーの音声を受け取り終えるまでの知覚遅延、モデルが最初の返答を決めるまでの反応遅延、そして TTS が最初の音を出すまでの音声化遅延です。従来の議論では、この全部が「レスポンス時間」としてまとめて扱われがちでしたが、実際には詰まっている場所が違います。
核心:何を提案したのか
提案の核心は、応答を一つの塊として生成しないことです。DDTSR では、最初に出せる短い接続句と、その後に続く本体応答を役割分担させます。軽量モデルは「安全に先出しできる談話接続」を担当し、大規模モデルは内容理解と本回答を担当する。両者を並列に動かし、会話として最も早く発話できる瞬間を前倒しします。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related