時空間物理系の表現学習は何を目指すべきか:次フレーム予測ではなく物理パラメータ推定で測る
時空間物理系の機械学習では、次フレーム予測の上手さが重視されがちですが、著者らは「下流の科学タスクに効く表現が本当に得られているか」を物理パラメータ推定で測る方向へ視点をずらします。 比較の結果、画素を直接当てにいく VideoMAE や自己回帰型の物理モデルより、潜在表現空間で未来を当てる JEPA 系のほうが、物理的に意味のある情報を保持しやすく、少ない fine-tuning データでも強いことが示されます。 重要なのは「物理システム向けに見える手法なら必ず有利」という結論ではない点で、物理モデリング専用手法の中でも差があり、表現学習の目的関数そのものが物理的有意味性を左右する、というのが主張の芯です。
TL;DR(結論)
- 時空間物理系の機械学習では、次フレーム予測の上手さが重視されがちですが、著者らは「下流の科学タスクに効く表現が本当に得られているか」を物理パラメータ推定で測る方向へ視点をずらします。
- 比較の結果、画素を直接当てにいく VideoMAE や自己回帰型の物理モデルより、潜在表現空間で未来を当てる JEPA 系のほうが、物理的に意味のある情報を保持しやすく、少ない fine-tuning データでも強いことが示されます。
- 重要なのは「物理システム向けに見える手法なら必ず有利」という結論ではない点で、物理モデリング専用手法の中でも差があり、表現学習の目的関数そのものが物理的有意味性を左右する、というのが主張の芯です。
なぜこの問題か
時空間物理系に対する機械学習は、長いあいだ「次のフレームをどれだけ正確に予測できるか」を中心に発展してきました。流体、対流、粒子系のようなダイナミクスを対象にすると、数値シミュレーションは高価であり、それを置き換えるサロゲートモデルを作れれば実用価値が高いからです。そのため、過去数フレームから次フレームの画素値を当てる、あるいは未来の場全体をできるだけ忠実に再現する方向が自然に主流になってきました。
核心:何を提案したのか
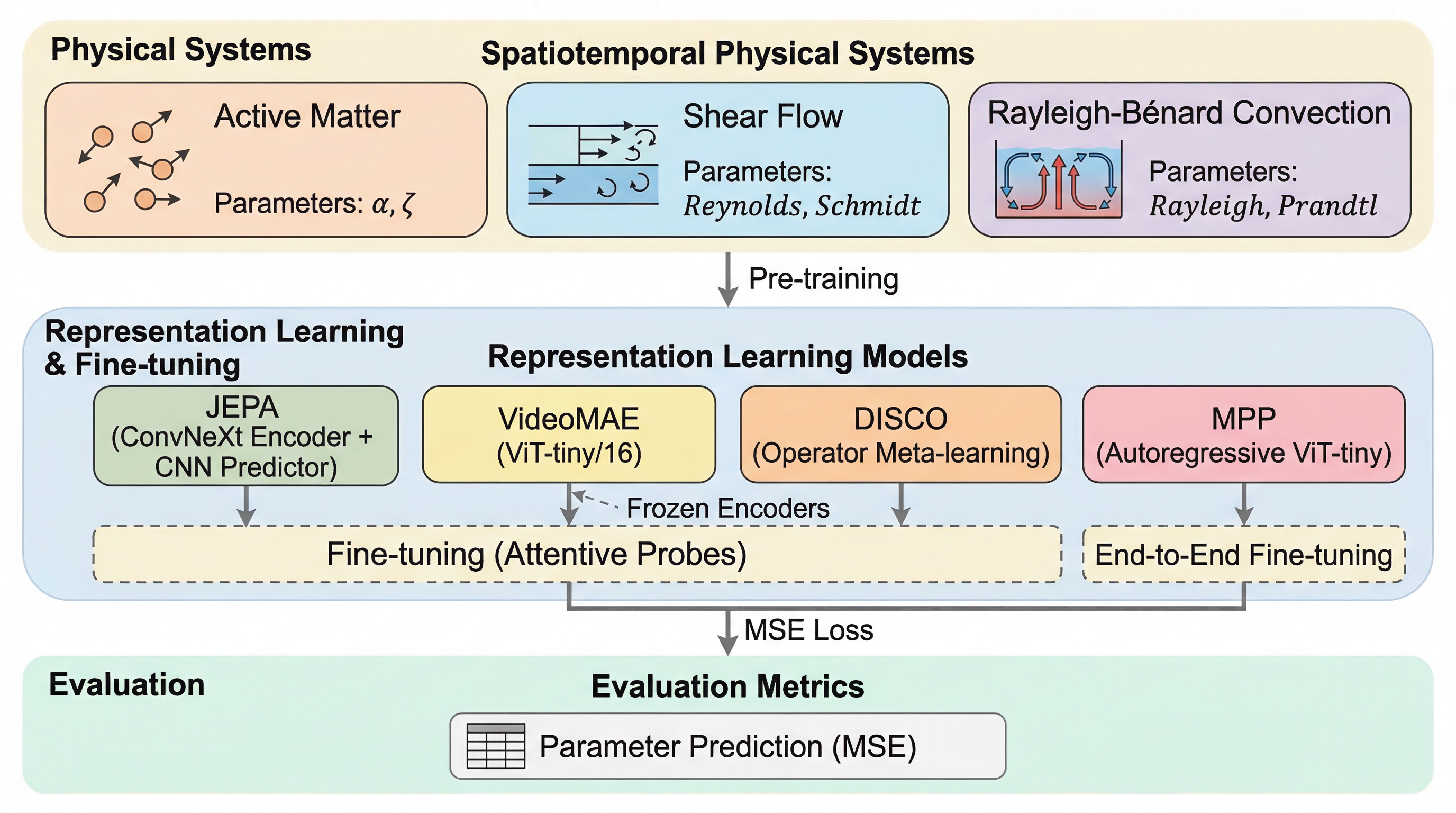
中心にあるのは、新しい巨大モデルの提案というより、物理系の表現学習をどう評価し、どの学習パラダイムが物理的に意味のある表現を作りやすいかを比較する実験枠組みです。比較対象は大きく四つあります。潜在表現空間で未来を当てる JEPA、画素再構成を目的にする masked autoencoding、物理モデリング系ベースラインとしての DISCO、そして自己回帰型 foundation model 的立場の MPP です。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related