大規模言語モデルにおける信念に導かれたエージェンシーとメタ認知モニタリングの兆候
大規模言語モデルは「自分が何を信じているか」を、内部で持っているのでしょうか? 意外なのは、その問いを“哲学”の言葉遊びで終わらせず、内部表現を実際に操作し、しかも計測して確かめようとしている点です。
論文図解
TL;DR(結論)
- 本論文は、意識そのものを評価せず、Butlin et al. (2023) の指標の一つ「HOT-3」をLLMで操作可能な形に落とし込みます。つまり大きな問いを、測れる問いへと切り分けて扱います。
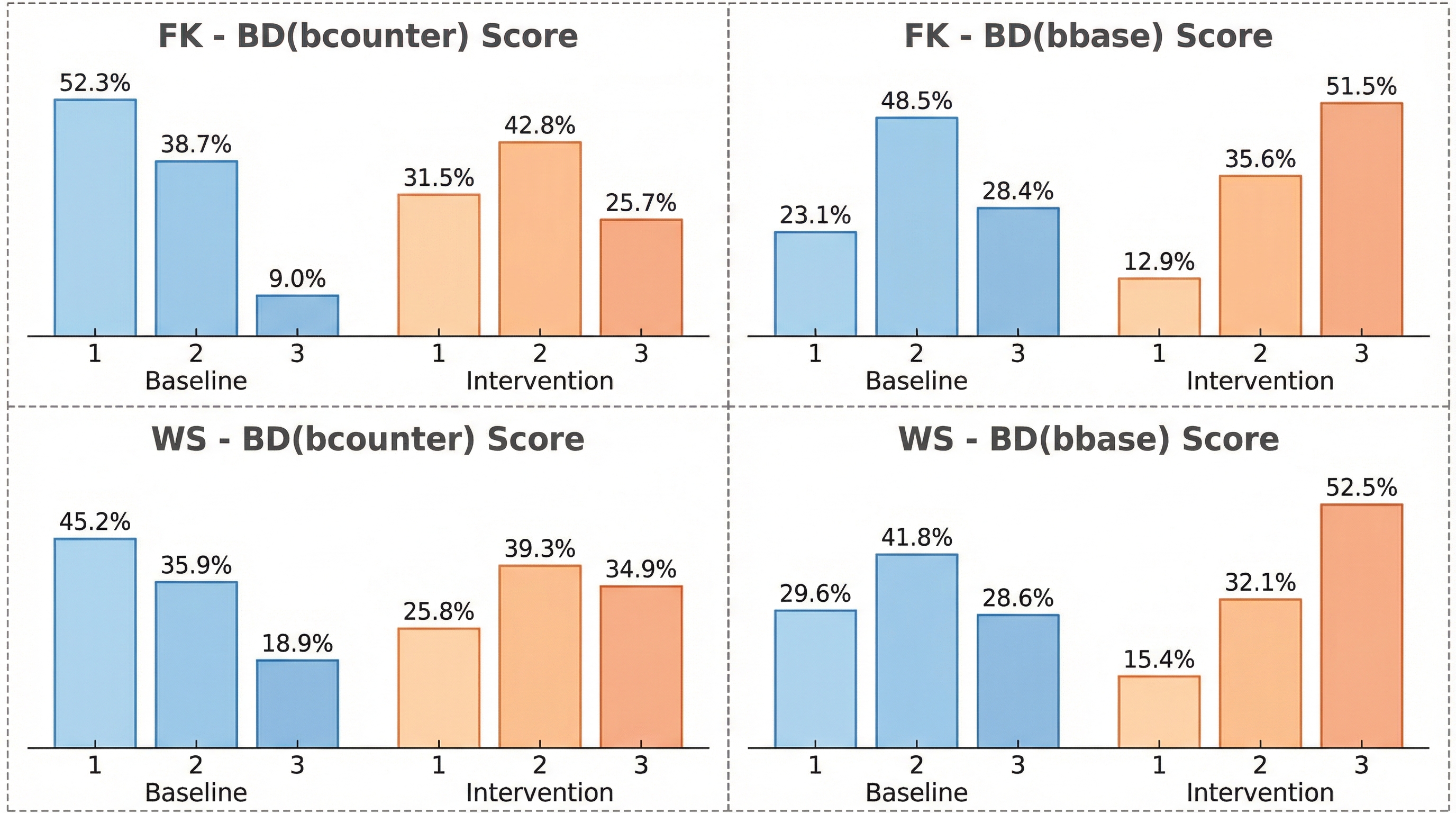
- 潜在空間の「信念」をBelief Dominance(BD)として定量化し、外部入力が信念形成を動かし、その信念が最終出力(行為選択)を押す様子を検証します。信念を“真偽”ではなく“内部での優勢”として扱うのが肝です。
なぜこの問題か
LLMの進歩は、「これらのモデルに何らかの意識があるのか」という問いを呼び起こしました。とはいえ、そのまま問うと、どこからが比喩でどこまでが検証可能な主張なのかが曖昧になり、議論は抽象に流れがちです。とくに「意識」という語は強すぎるため、観察できる現象と結びついた形にしないと、結論が“印象”に寄ってしまいます。
核心:何を提案したのか
本論文が評価対象に据えるのは、指標の一つであるHOT-3です。HOT-3は、ざっくり言えば次の2点を要求します。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related